Jump to app 👇
Whoa, cowboy! Sure coming in hot with that chart, huh? Well, that’s what I gotta do, to have social media preview text show this image.
Now then, I guess some context is in order.
This whole rabbit hole started, as most things do, with an errant social media post.
Not gonna lie. This FB repost of a Twitter RT put me in full on panic mode. I thought I had 66 “sighs” in my upcoming manuscript. (Turns out I only had 47, the rest were versions of “sight”).
Is that too much? DOES MY HEROINE SIGH TOO MUCH? And more importantly, are there any other words that stick out like sore thumbs in my work? How can I possible find out.
English word corpi, that’s how. (Yes, turns out that I’m not only going to come at you with charts out of context. I’m also going to hit you with weird latin words.) What I found was the Brown Corpus of American English, over 1 million words of texts that are representative of written American English. Thanks to their liberal search engine, I was able to “borrow” (cue: Dr Evil air quotes) the half of it that had frequencies of more than 1 word making an appearance in the whole collection. So basically, if it’s not on that list, it is a rare word.
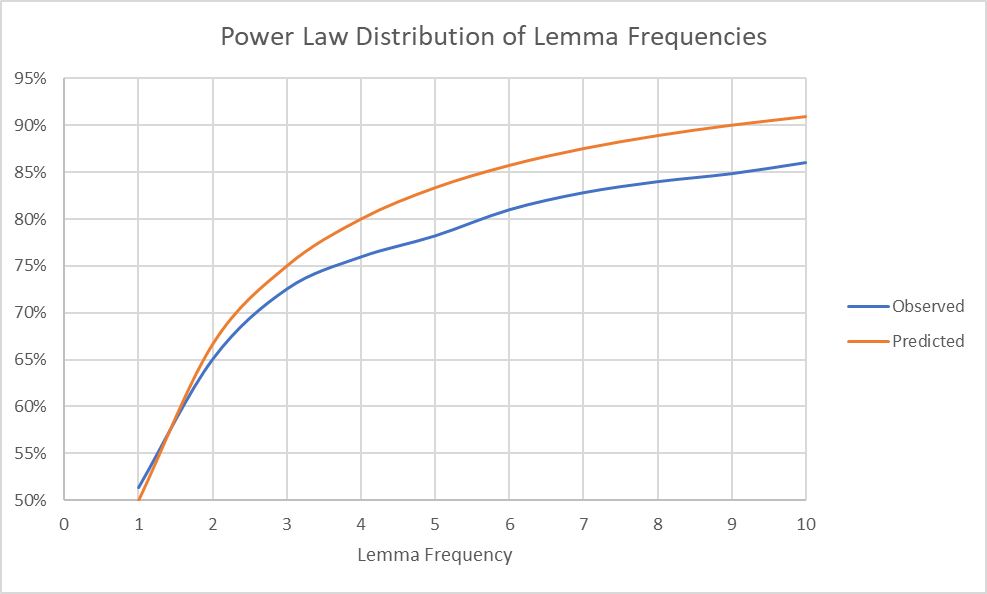
In my process of leveraging scraping to abuse their good natures, I discovered an interesting power law of what I am assuming is a global pattern in human speech, but I can only verify inside the Brown corpus. This is probably a retread of Zipf’s Law, but so be it. When you list the words, together with the number of times they appear in the corpus, the words that only appear once take up half of that list. If you take the words that appear either once or twice, they take up about two thirds of that list. The pattern actually continues (not very well, but it may be because I found it in a 1% audit of the corpus).

That’s the graph you see at the top of the article: the formula above (predicted) vs the observed counts of words at certain frequencies, cumulative.
Does anybody remember where this article was going? Ah, yes, Sore Thumb words. So now that I have my frequency list from the Corpus of Unusual Size (representing 90% of the full corpus), I can compare frequencies of each word to the frequencies in my manuscript.
After I turn the words into lemmas. Oh, great, more jargon. Basically, I need a way to turn all tenses an plurals into present tense singular, or the lemma form of the word. Is there nuance in that definition? Probably, the world is complicated, and I’m a linguistic duffer. So after struggling to find a lemmantizer that works outside of NodeJS (spoiler, there isn’t. Or WASN’T, until I showed up. You’re welcome.), I was then able to code the first version of the program.
Which hung the browser. Because crunching all those words is not really what devs had in mind when they built Javascript. But I was determined to keep this platform agnostic, because while I write in Windows, all those stereotypical creatives like Mac. Also, I wanted to keep the processing client-side, so nobody felt like I was taking their manuscript up into the cloud to do untoward things upon it.
So I struggled to learn JS asynchronous calls. Let me tell you, this isn’t for the faint of heart. But then, after trying to learn Promises, and the Await syntax, I run into a post that says the only truly asynchronous functions in JS are a small handful of baked in, purpose driven ones. Which explains why all my attempts are failing (or I’m old, and my mind grows too rigid to comprehend new topics).
So I set all my sloth functions to setInterval, which by my calculation adds a 6 millisecond tax to EVERY WORD I CRUNCH, which really adds up over thousands of words.
But at least the program no longer hangs.
So at long last, I present to you, The Word Frequency Comparison App. There are still some bugs, like it doesn’t turn “was” into “be”, like it should. When people notice them, if they’d be kind enough to reach out and tell me through the Contact Us page, that’d be great.
Epilogue: My 47 instances of “sigh” represented 0.054% of my manuscript, as opposed to the Brown corpus, where it is 0.051%. It turns out my heroine does not sigh too often, after all.
0 Comments