Edit: Have just been informed, Audible sets the price of books. Oy Vey what a waste of time.

In case you want context for that picture, those are the titles of all the UF books on Audible that have at least 1 rating. The size of the text is proportional to the natural logarithm of the amount of ratings it has. Looks like Jim Butcher / James Marsters are #winning.
So my audio book is finished, and waiting for approval by the Audible QA process before being on the store. Meanwhile, I have to figure out how to price it. It’s either not as easy at it seems, or I am classic data scientist over thinking it.
I started by writing a script to grab prices and run lengths of the first 50 UF book that come up on a search in audible, and after removing outliers in length and price, get the following data:
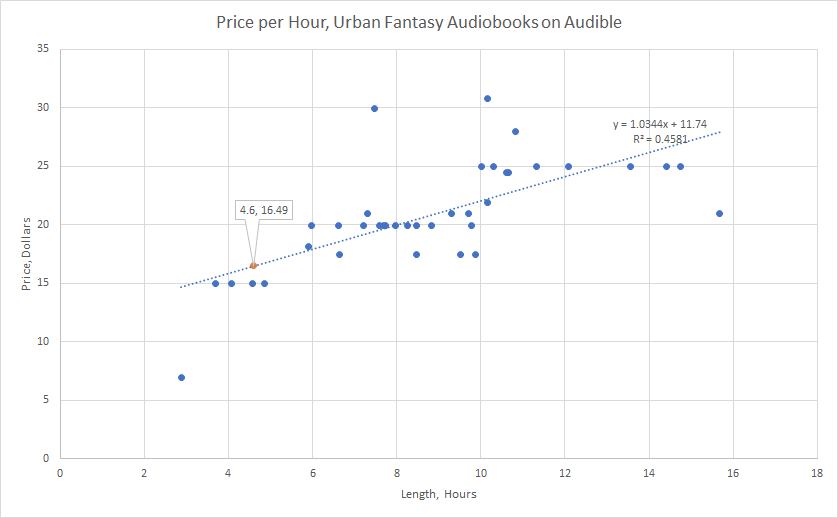
Posted it on Fans of Urban Fantasy, and there was a fair good consensus that even knocking it down to the minor cluster that exists near my book at $14.99 is “too expensive for a short book”. I am absolutely new to the scene, and happy to listen to the customers.
That get’s me thinking, maybe I should see if there is a relationship between popularity of the book and run length with price. Maybe if I confine it to less popular books, I’ll get a better price point.
Grabbing ALL the UF books on audible (937 at time of this post) is actually a days long process, even though I have a few days off to bash my head against the problem. My phone, where I wrote the original script, ran into memory over runs and the script was closed by the system. It must be some of the tools I’m invoking.
‘K, this looks like a good time as any to learn how to use Power Automate Desktop. (Can anyone else hear famous last words?) Well this is remarkably thorny as PAD has some weird variable syntax and wonky ways of performing common steps, but its a code blocks environment, so it’s still quicker to prototype than C#. So after a lot of cresting the learning curve, and a few very “duh!” errors by me, I’m able to download everything.
Seriously, it would be easier and quicker to grab all this by hand at this point, but I know if I give up now, I’ll always remember PAD as the tool that got away from me, so onwards!
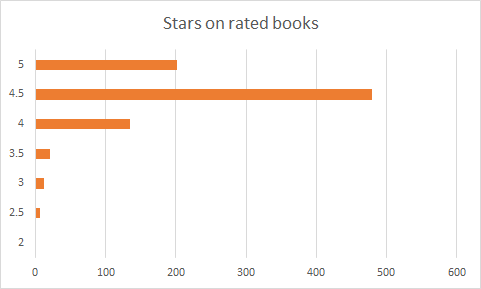
The median and IQRs of the 937 data points was as follows: Length – 8.7h (6.3-11.6); Price – $19.95 ($17.49-$24.95); Ratings – 38 (6-160). 81 were unrated. Stars on rated books below, I didn’t find that info particularly valuable given how many were 4 and greater.
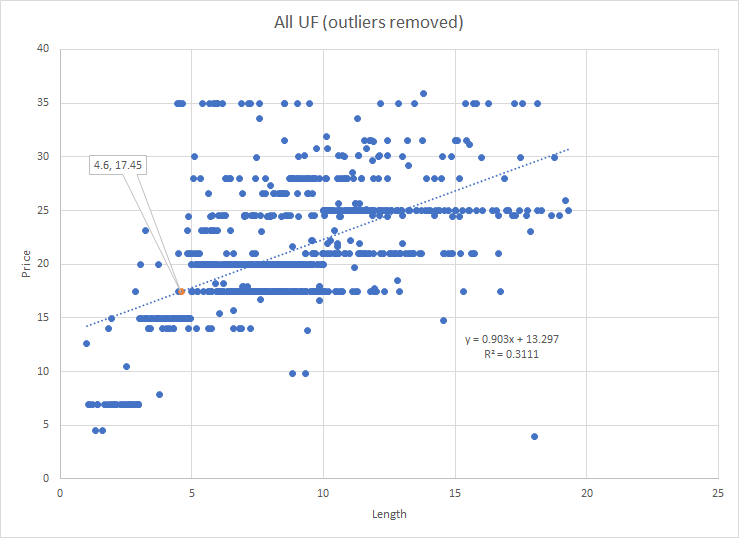
When you remove datapoints beyond the upper whiskers of price and length, you get the following picture:
What you can start to see is a step pattern emerging: Below 3 hours, $6.99, 3-5, $14.99, 5-10, either $17.49 or $19.99, 10-20, $24.99. This pattern is going to come up again, no matter how you slice the data.
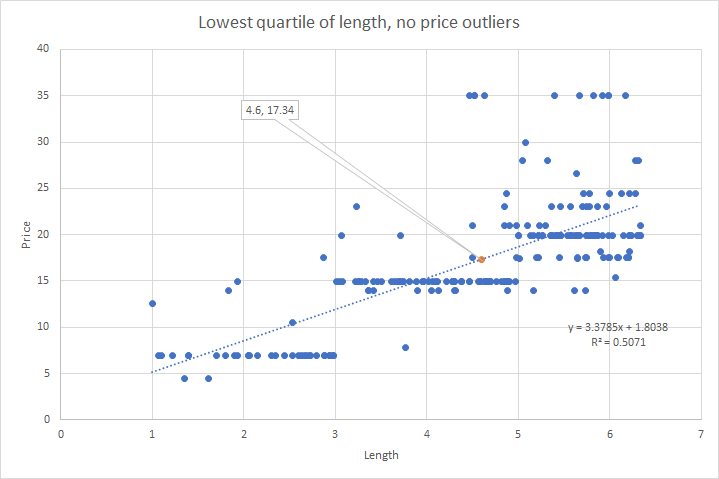
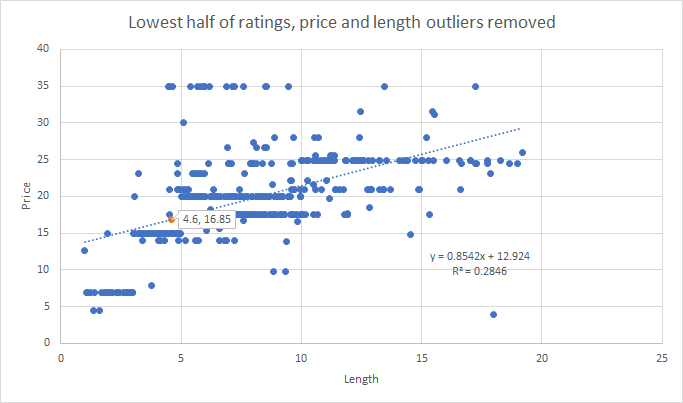
As you can see, that step pattern appears again and again. For S&G, I performed a multiple linear regression of price by length and rating, with the following results, which prices me out at $17.63, assuming 4 reviews I have on my book on Amazon thus far:
| Attribute | Coef. | std | t(671) | p-value |
|---|---|---|---|---|
| Intercept | 14.314501 | 0.481003 | 29.759692 | 0.000000 |
| length | 0.715082 | 0.051404 | 13.910965 | 0.000000 |
| ratings | 0.005405 | 0.002196 | 2.460946 | 0.014108 |
Long story short, it seems that the price everyone else is putting on their book from 3-5 hours is $14.99. Happy to hear comments about it down below.
My next step is to re run the data grab, this time getting release date. Perhaps the ratings are a function of how long the book has been out. Or perhaps people down price their books after a while of it not selling well.
0 Comments